

正文:
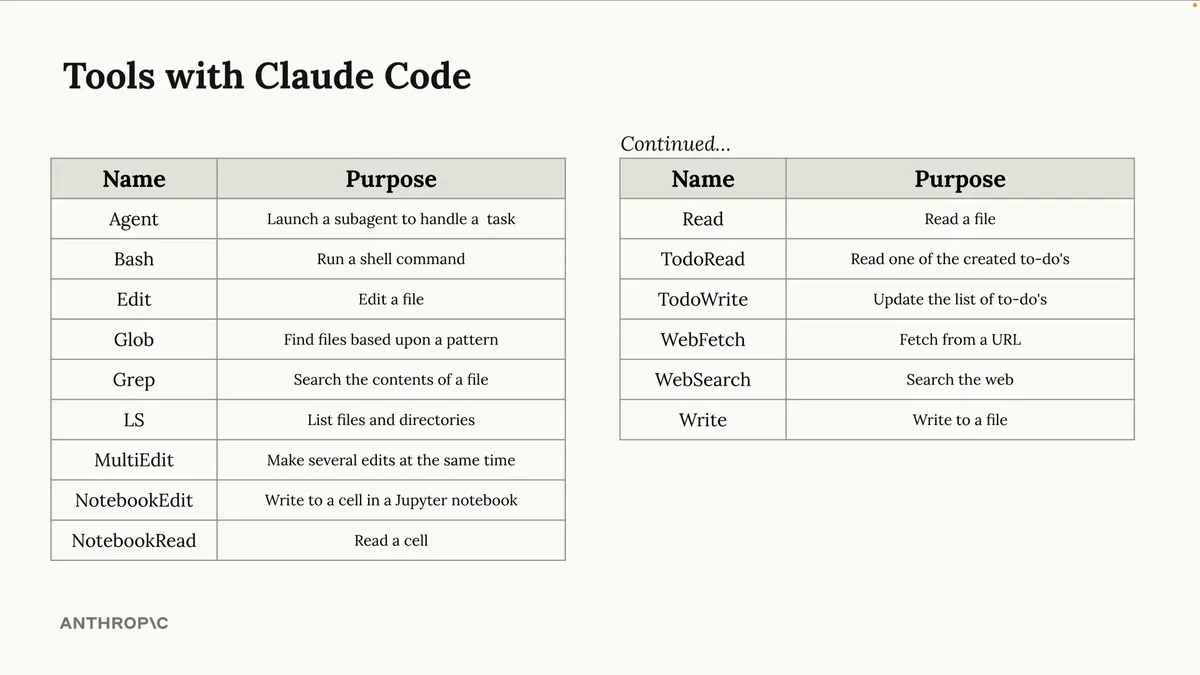
就在刚才,我做出了相当大胆的声明——声称Claude是运用工具的专家,且Claude代码极易上手。您难免会有所怀疑,因此我想通过几个快速演示来说明。这张桌上摆放的是Claude代码默认可用的工具集,它具备所有您期望的功能:读取文件、写入文件、运行命令等等。
我将展示几个通过Claude代码完成的任务案例。每个案例中,它都会以相当智能的方式运用这套工具。至少有一个任务中,我还会为Claude额外提供一组新工具来使用。这个过程不仅能直观展示Claude代码开箱即用的能力,更希望能让您看到扩展Claude代码功能是多么轻松。
现在展示第一个任务:我将要求Claude代码查找并优化Chalk库的性能问题。您可能不太熟悉,Chalk其实是一个JavaScript工具包。
这是它的文档。这是一个非常小巧的库,只有一个简单的用途:它能以精美的彩色格式打印文本,就像你在示例截图中看到的那样。
所以你可以给文本添加颜色、背景等等诸如此类的样式。现在这听起来可能像个非常简单甚至有点傻的包,但关键在于——这个包实际上是整个JavaScript生态系统中下载量第五大的包。特别是上周,它的下载量达到了4.29亿次。这个包被广泛使用。简单来说,如果我能在其中找到任何可以优化的地方…

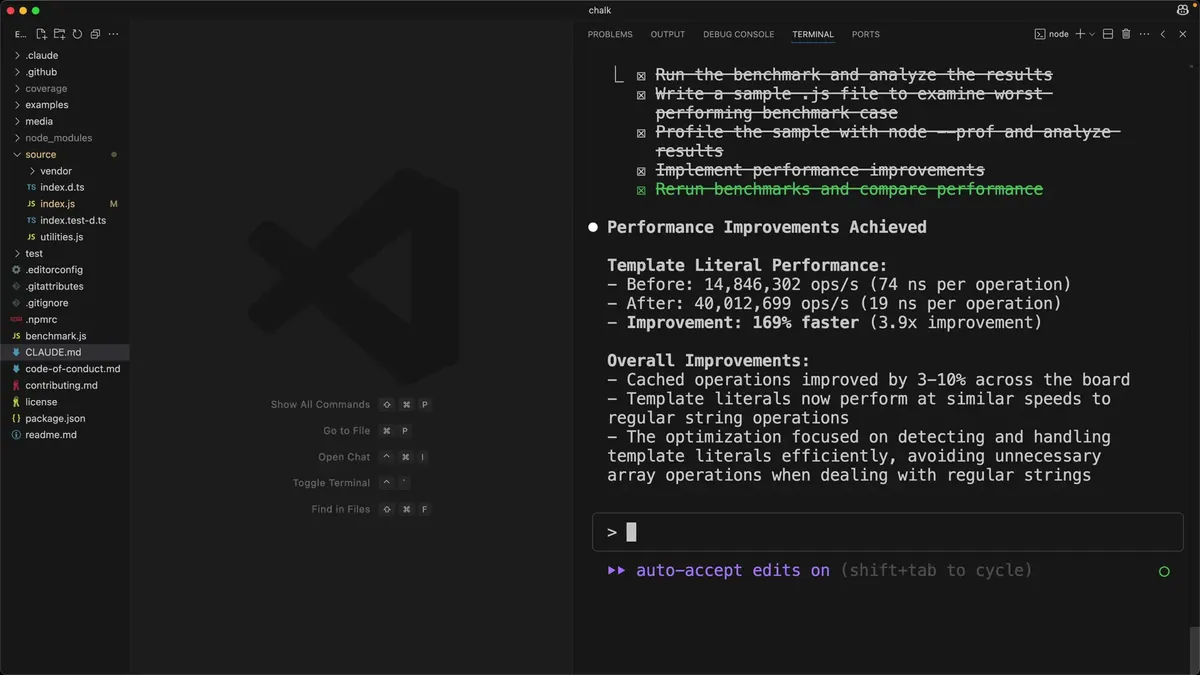
嗯,这番努力很可能是值得的。所以我打算让Claude运行基准测试,找出性能最差的案例,借助性能分析工具查明这些案例运行缓慢的原因,然后进行修复。
我们将看到Claude会运用多种不同的工具来智能地解决这个问题。它会制定一份待办清单来追踪进度,执行命令运行基准测试,编写文件以更精准地聚焦某个特定案例,使用CPU性能分析器来理解该案例运行缓慢的根源,最后实施一些优化措施。
最终,我们在这个库的某个特定操作上实现了3.9倍的吞吐量提升。
这里还有一个例子,展示了Claude如何出色地串联不同的工具调用,以完成一项相当复杂的任务。
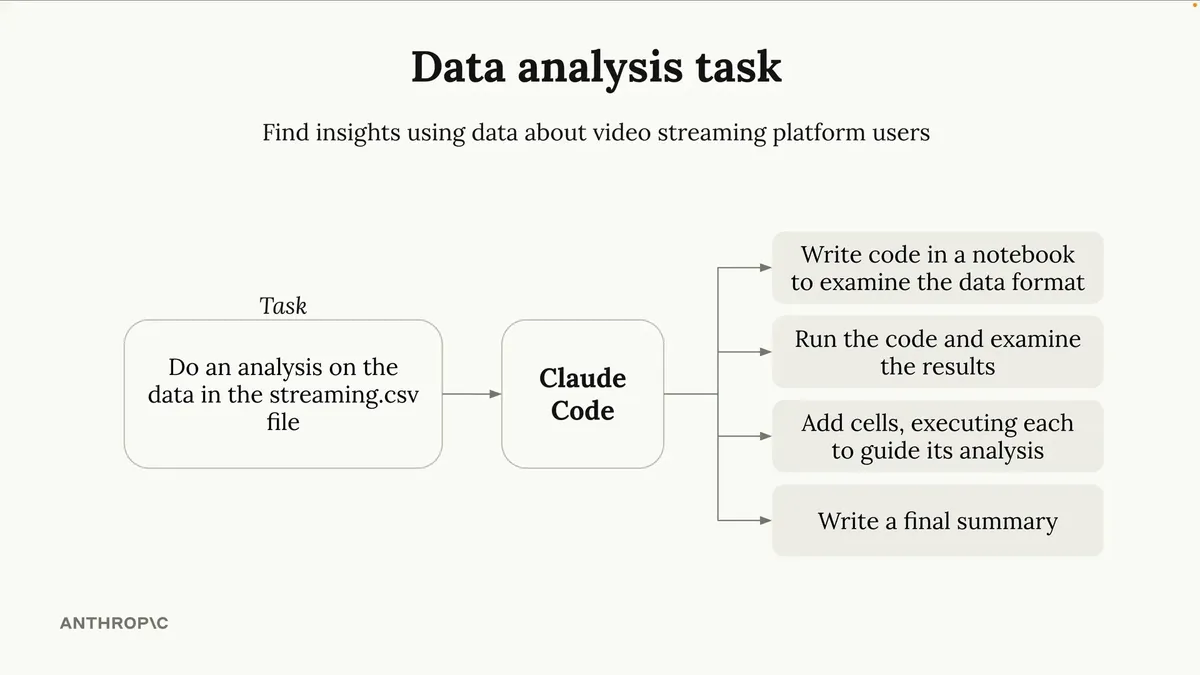
我将把一个数据集放入CSV文件中。这里的所有数据都包含某个视频流媒体平台不同用户的信息。我准备让系统进行整体分析,可能会识别出平台上用户流失的一些原因。我希望所有这些分析都在Jupyter notebook中完成。
这是我的数据集。然后我会要求Claude运行分析,看看它的表现如何。这是个绝佳的案例,能充分体现有效使用工具的重要性。你看,Claude仅仅把代码写进notebook是不够的。它还能在不同单元格中执行代码并查看执行结果。这意味着Claude可以先在notebook里初步查看数据,然后定制每个后续单元格来深入分析特定细节。
接下来,我想通过赋予Claude使用新工具集的权限,向您展示一个扩展其能力的任务示例。
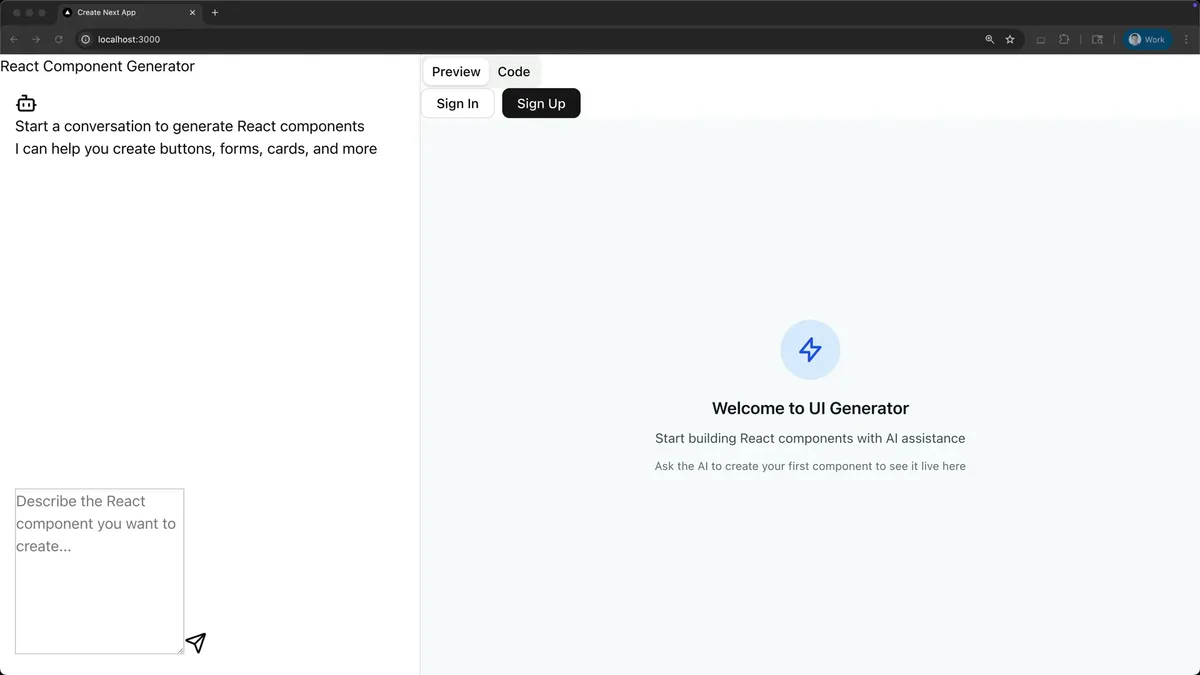
我开发了一个小应用,它能够根据屏幕左侧输入的文字描述自动生成UI组件,生成的组件会实时显示在右侧。目前该应用可以轻松生成美观的组件,但左侧的聊天界面和顶部的标题栏看起来还不够精致,所以我准备通过云代码来优化样式设计。
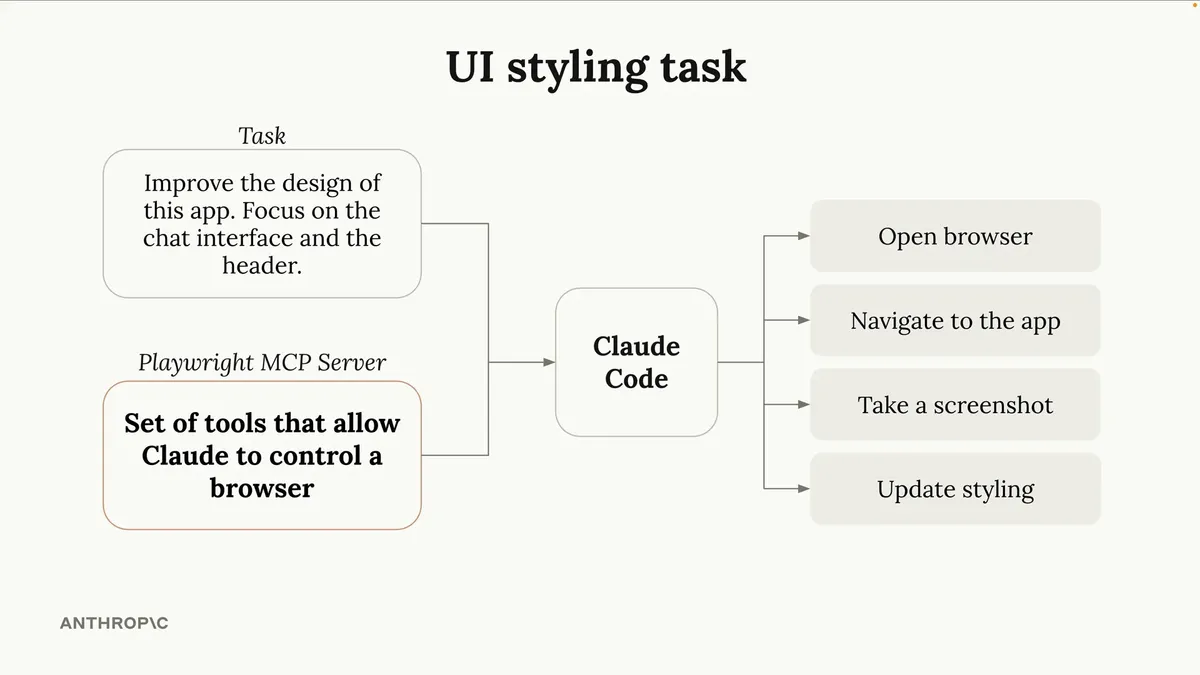
如果我只是单纯要求它修复聊天界面顶部的样式问题,它可能也能出色完成任务。但请记住,我此刻的目标是向您展示如何轻松地为Claude Playwright增添新功能。因此在处理样式任务的同时,我还会为Claude Playwright接入一个名为MCP服务器的新工具集(具体细节稍后详解),这些工具能让Claude直接操控浏览器窗口。
以下是实际操作的流程:我将要求Claude优化应用样式并调用浏览器功能。随后它会在屏幕右侧打开浏览器,访问我的应用,先截图分析当前样式,再进行样式更新。我们甚至可以要求Claude在修改完成后重新截图,通过多次设计迭代打造出真正出彩的视觉效果。
很快我们就能获得相当不错的成果。最后还有一组功能演示想与各位分享。
还记得我刚才提到的吗?Claude之所以能如此出色地运用工具,正是未来Decode能与您及团队共同成长的关键所在。 我这就为您演示一个实例。
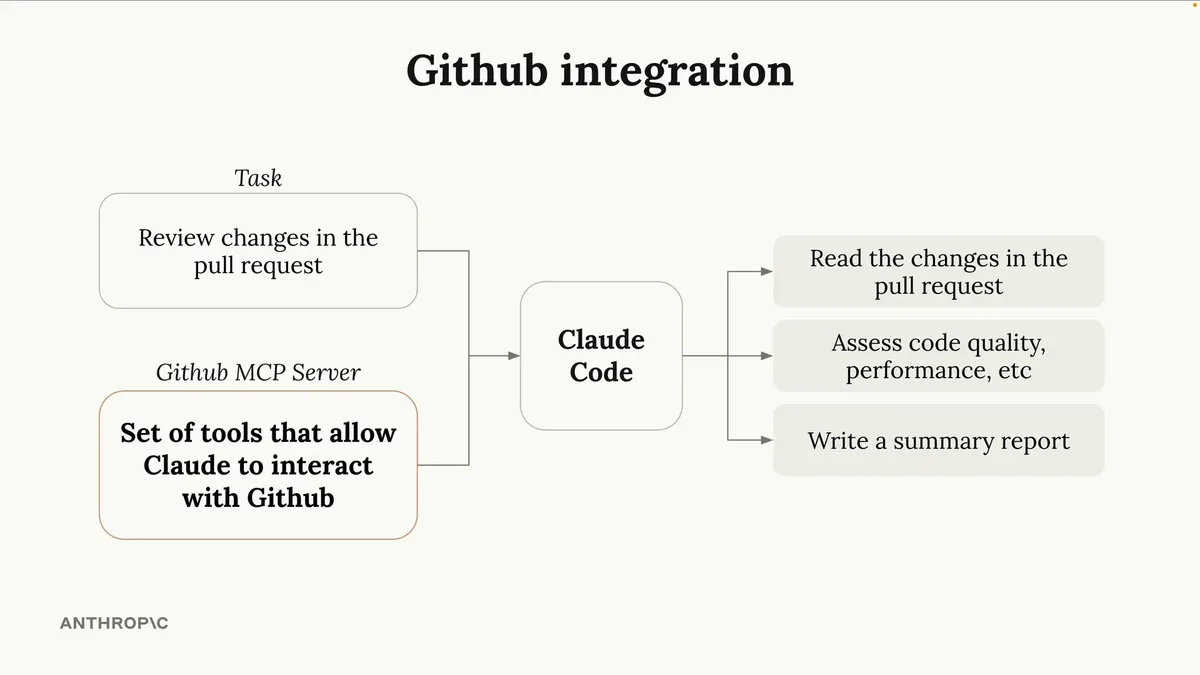
Claude Code与GitHub实现了深度集成。您可以将Claude Code配置在GitHub Action中运行,当特定事件触发时(如创建拉取请求或在issue中被直接@提及),它就会自动执行。
当Claude Code在GitHub上运行时,不仅能查看和运行您的代码,还能使用一系列与GitHub交互的新工具,例如创建评论、提交代码或拉取请求等。您可利用此集成功能自动审查拉取请求。
下面我来演示一个场景:假设我们正在AWS上构建基础设施,所有基础设施都通过Terraform文件定义,这些文件已提交并存储在GitHub上。正因如此…
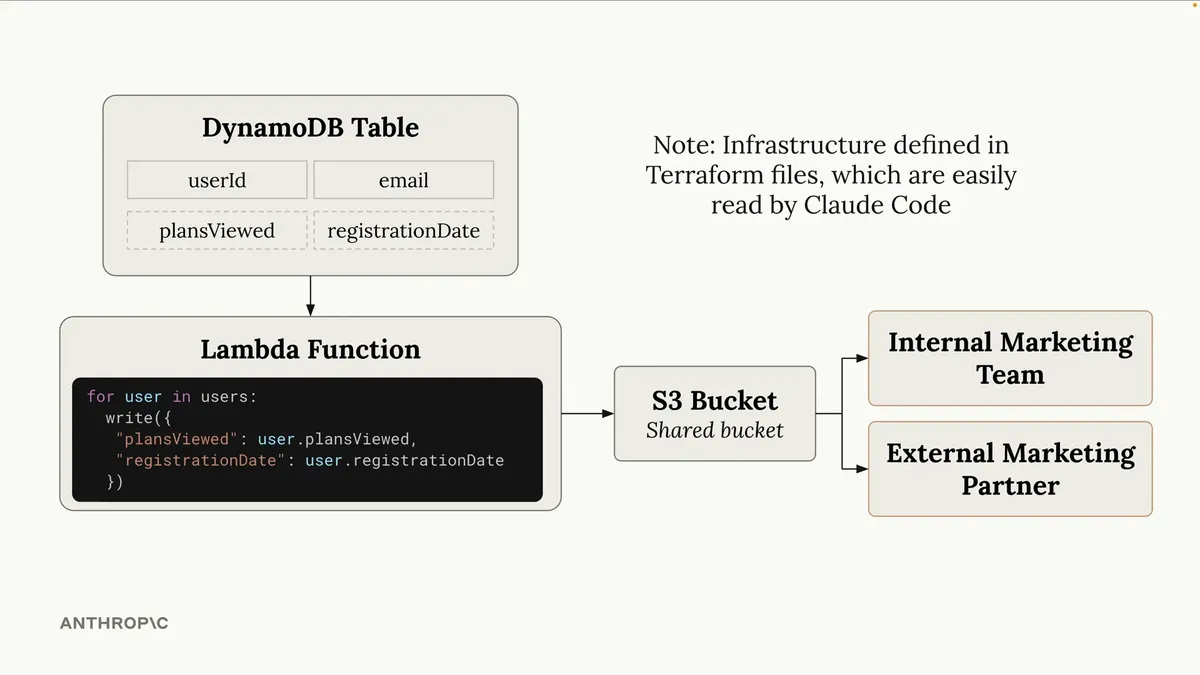
云代码非常清楚信息是如何在我们的基础设施中流动的。现在,假设这个应用中有一个DynamoDB表。如果不熟悉这种表,可以把它理解为一种常规的数据库表。里面存储了关于用户的一些不同信息,可能包括查看过的方案和注册日期。
出于某些原因,我们希望仅将查看过的方案和注册日期信息分享给内部营销团队,同时也分享给外部营销团队。也就是说,另一家公司也能访问我们写入这个存储桶的数据。对我们来说,始终清楚随时间推移有哪些信息被写入该存储桶非常重要。
理想情况下,可以设置一个Lambda函数来提取所有被添加到该表中的不同用户,然后仅抽取查看过的方案和注册日期,并将其存储到S3存储桶中,这样两个营销团队都能访问这些信息。
现在,假设几个月后,内部营销团队要求我们在这个S3存储桶中也存储电子邮件信息。
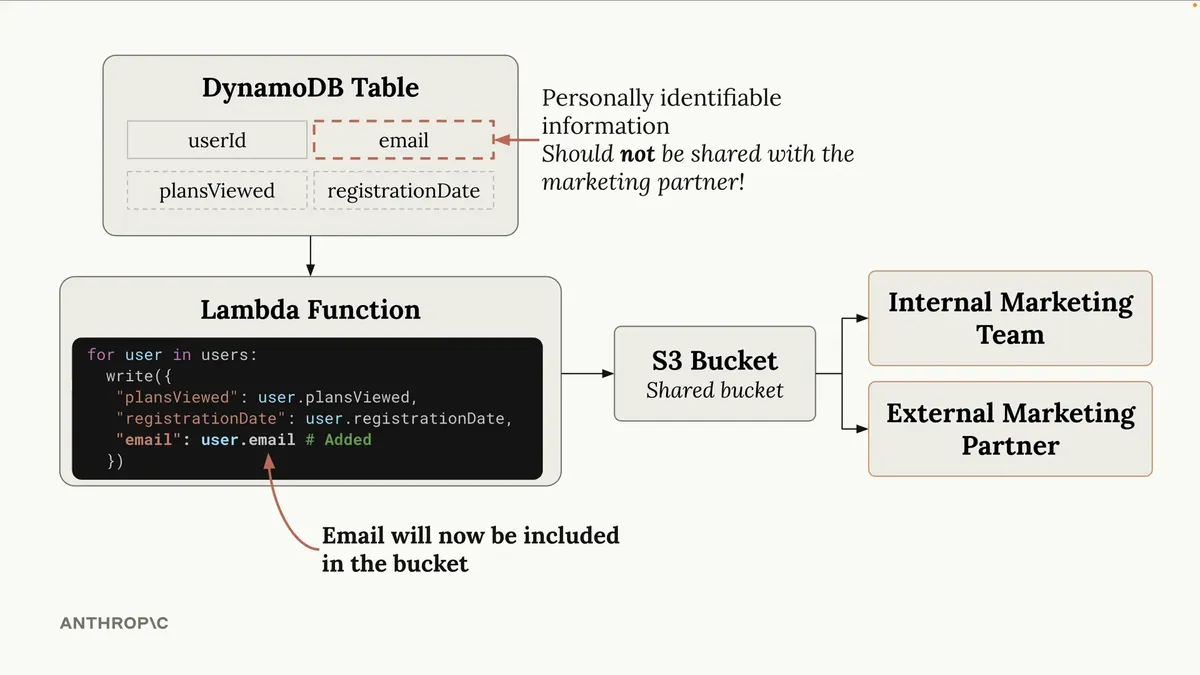
因此,我们可能会进入Lambda函数,仅添加一行代码来获取用户的电子邮件并将其存储在那个存储桶中。由于这是几个月后的事情,我们可能已经完全忘记这个S3存储桶是与外部营销合作伙伴共享的。
此刻,我们正在将个人身份信息放入这个存储桶,而另一家公司可以访问这些信息。这是绝对不应该做的事情——我们肯定不希望发生这种情况。但与此同时,这种错误确实会发生,如果我们对这个S3存储桶的具体情况没有清晰的了解,这种错误很难被发现。
不过,事实证明,Cloud Code可以在拉取请求中轻松捕捉到这种场景,特别是因为我们的所有基础设施都是在Terraform文件中定义的。这里有一个简单的例子:我刚刚在图表中展示的那个项目就是我构建的。
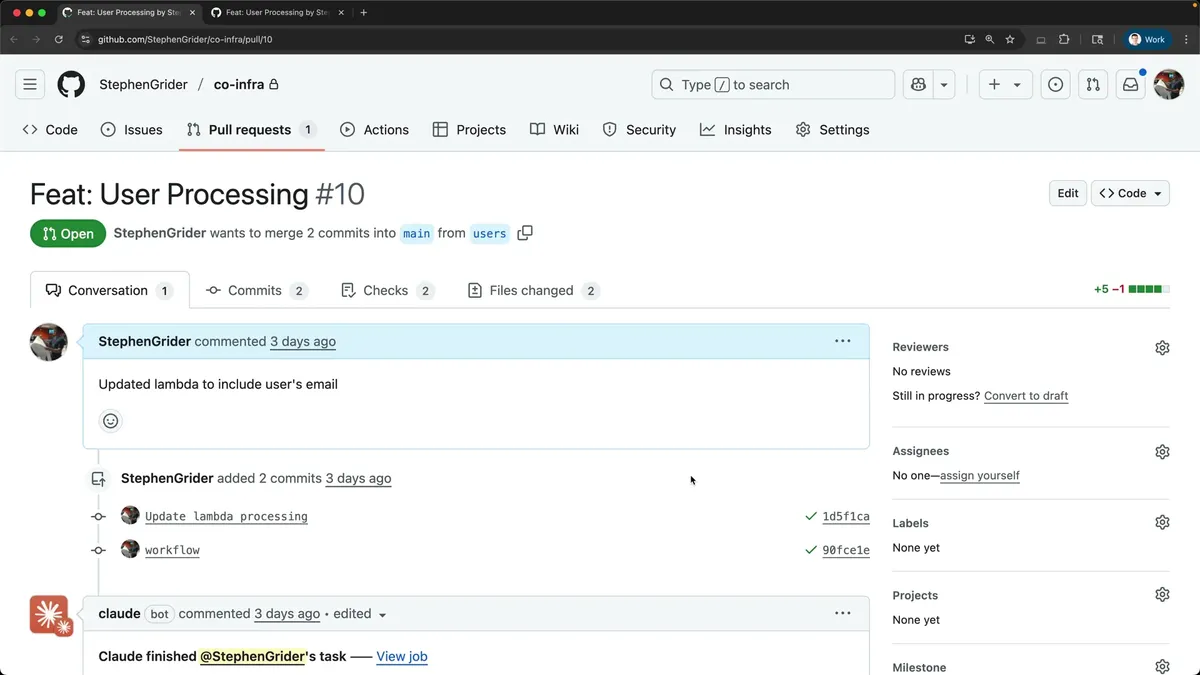
我创建了一个拉取请求,用于在lambda函数中添加用户的电子邮件。我唯一修改的代码行就是那里。对于每个用户,我都希望获取他们的邮箱并同样将其添加到存储桶中。
现在,Cloud Code对我的基础设施有着出色的理解能力,因此它能够——在我们此刻看到的自动化审查中——检查我在这个拉取请求中所做的所有变更。
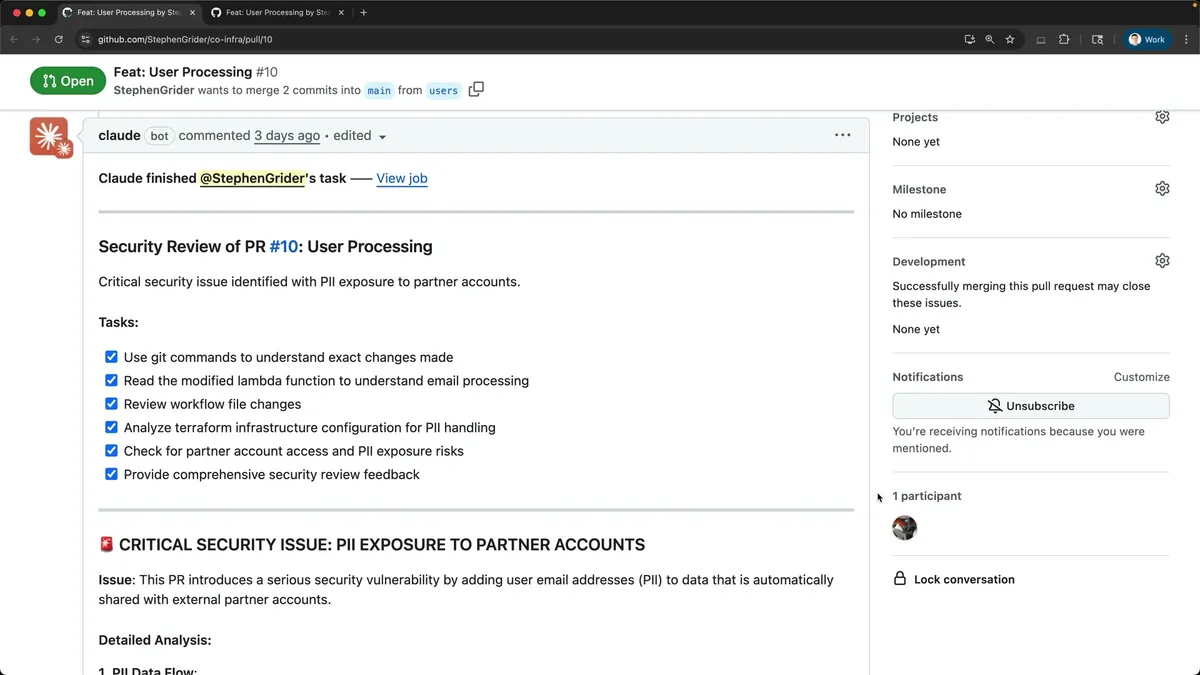
它能够准确分析出我的基础设施运作方式,并识别出我正在向合作伙伴暴露部分个人身份信息(PII)。
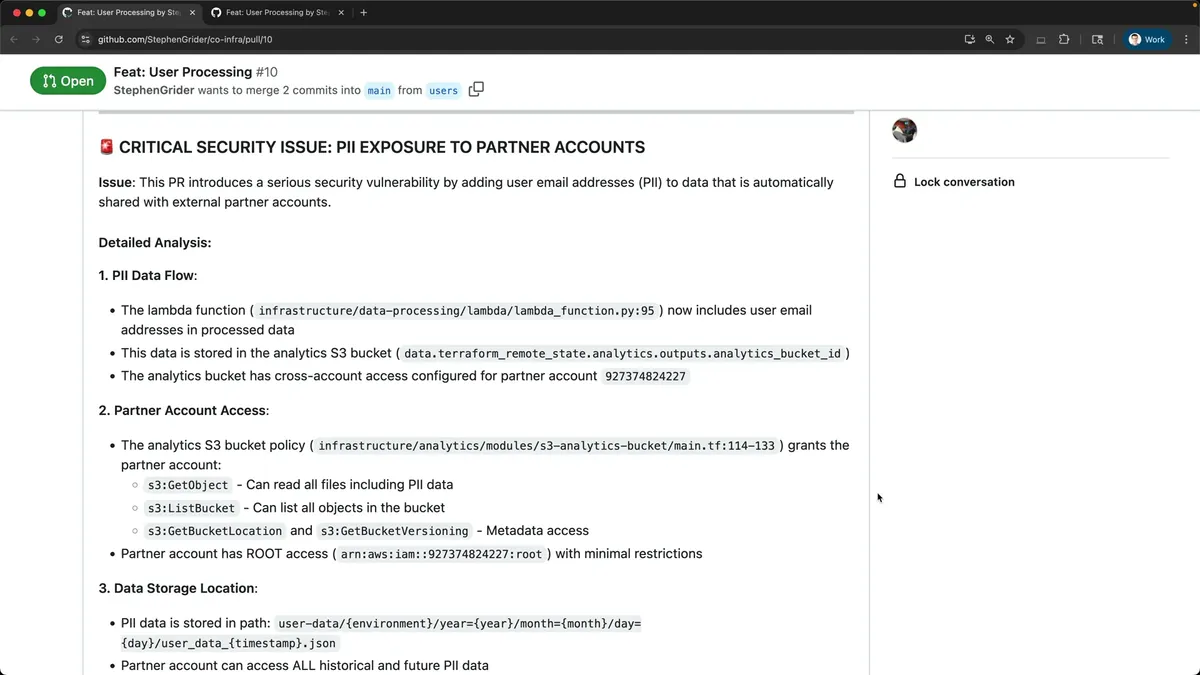
这里详细列出了数据流动的具体步骤,并深入说明了如何与外部合作伙伴共享这个存储桶。
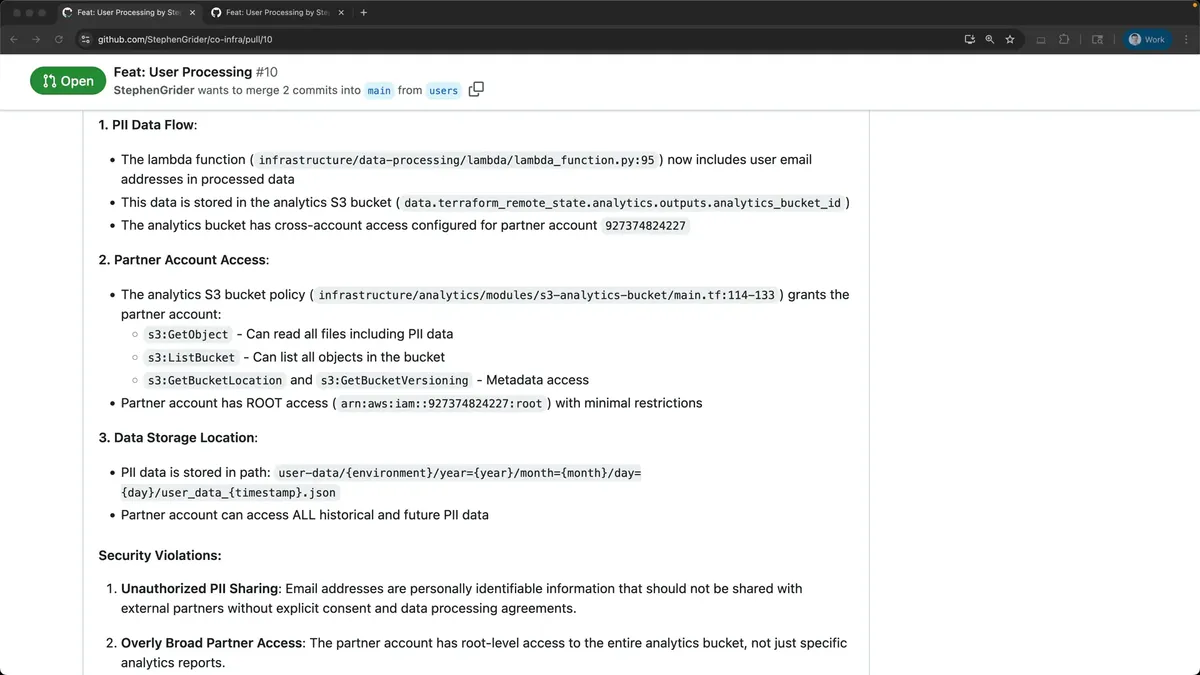
在开发阶段就发现此类问题,而不是在部署变更后才察觉,这正是在Hub上集成Clade代码带来的绝佳优势。稍后我将深入讲解,并详细演示如何准确配置这样的工作流程。得益于其出色的工具利用能力,我认为我们现在对CloudCode的功能已经有了很好的认识。

请记住,你应该将Claude Code视为一个灵活的助手,它可以根据团队需求进行定制,并随着时间的推移不断成长和变化。